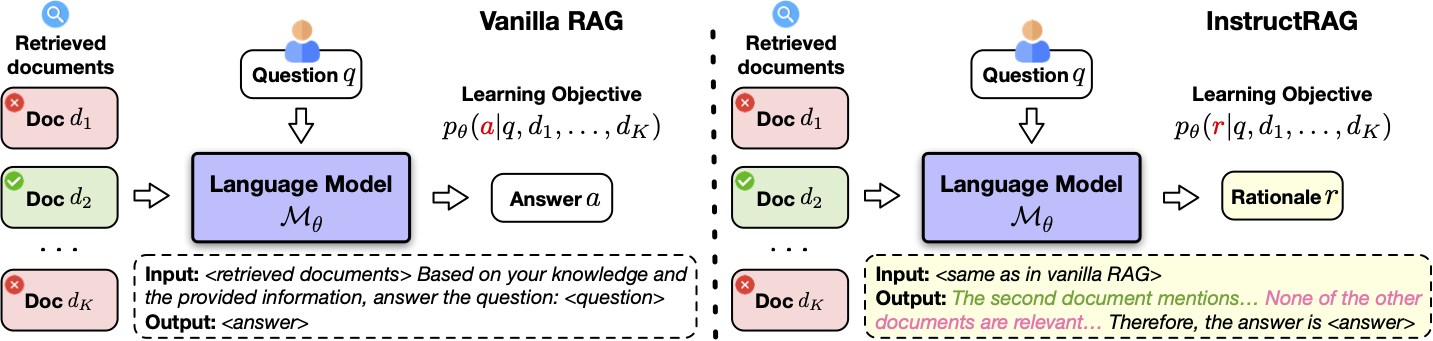
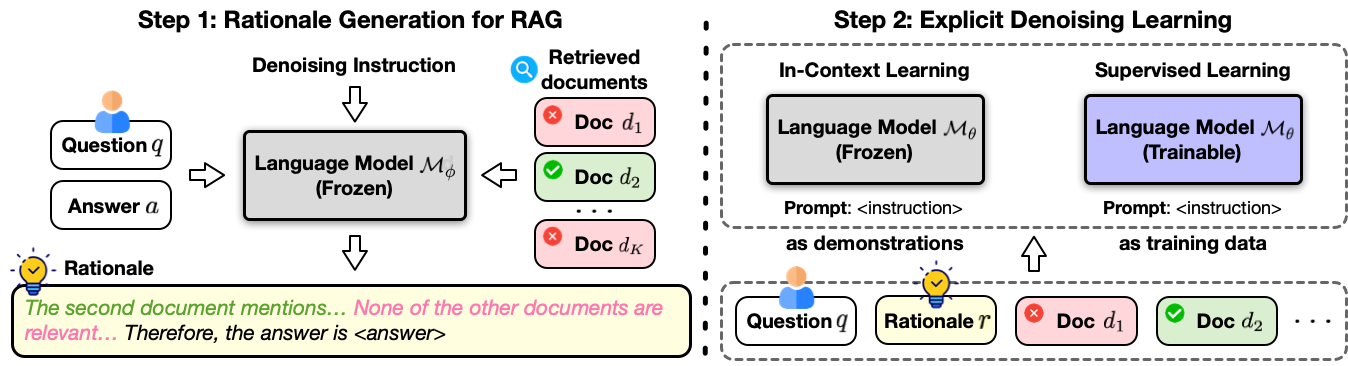
InstructRAG is a self-synthesis method that leverages instruction-tuned LMs to generate their own supervision for learning denoising in RAG. As shown in the following figure, our method consists of two steps:
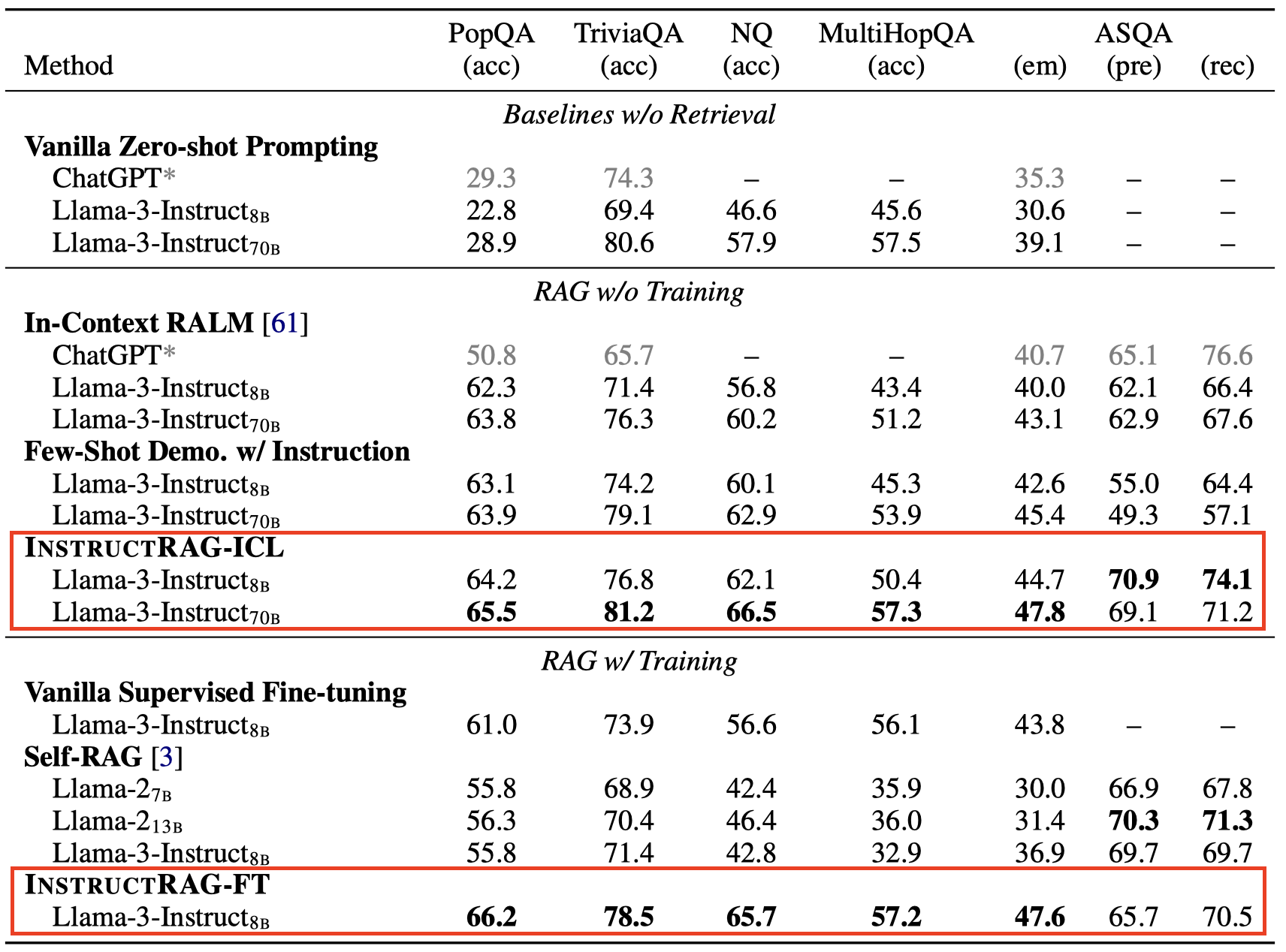
InstructRAG consistently outperforms baseline RAG methods across five knowledge-intensive benchmarks in both training-free and trainable settings.
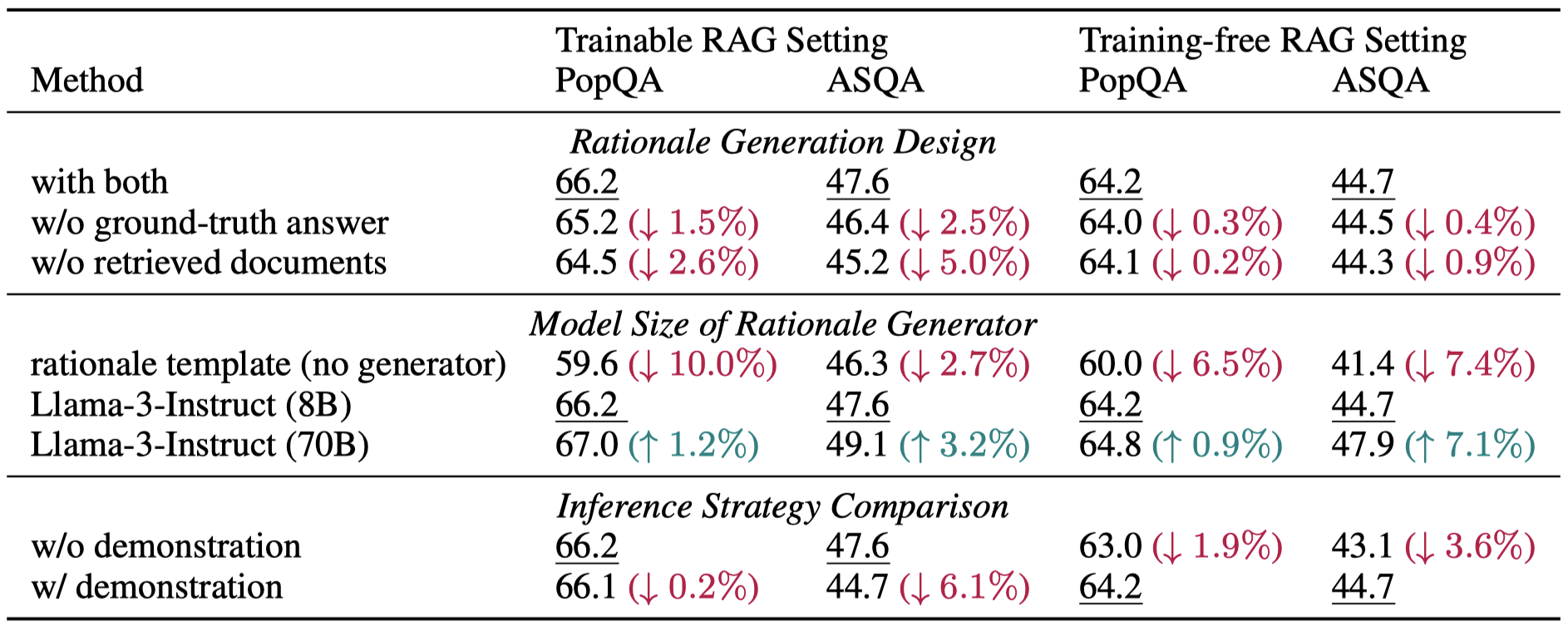
TL;DR: providing ground-truth answers and retrieved documents is important for rationale generation. As shown in the first block, we ablate the rationale generation design from two aspects: (a) w/o ground-truth answer, where the model has no access to the ground-truth answer during rational generation and must predict the answer and explain how it is derived solely based on retrieved documents; (b) w/o retrieved documents, where the model is not provided with any retrieved documents during rational generation, and in this case, it has to explain the given answer based on its own knowledge.
Larger rationale generator consistently leads to better results. The middle block shows how different sizes of rationale generators impact the performance of our method.
Inference with demonstrations should only be applied to InstructRAG-ICL. In the bottom block, we study the use of demonstrations during the model inference of InstructRAG.
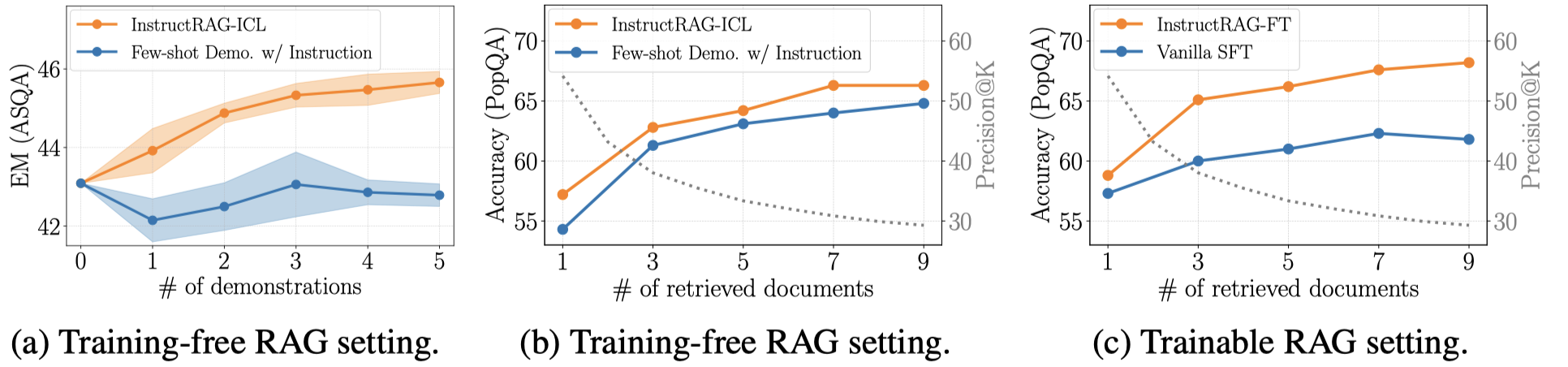
InstructRAG-ICL consistently benefits from more demonstrations. Figure (a) shows the demonstration sensitivity of InstructRAG-ICL and the few-shot demonstration with instruction baseline.
InstructRAG-ICL and InstructRAG-FT are robust to increased noise ratios. Figure (b) and Figure (c) show the generation accuracy of InstructRAG-ICL and InstructRAG-FT and the corresponding retrieval precision under an increasing number of retrieved documents.
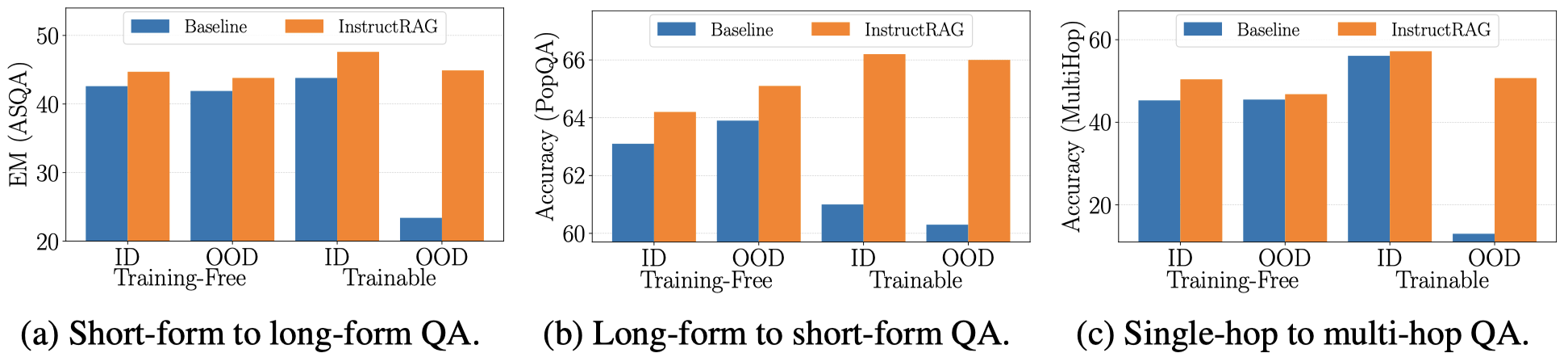
TL;DR: InstructRAG-ICL and InstructRAG-FT generalize well to unseen tasks. The following figure demonstrates the generalization ability of our method in both training-free and trainable settings. For the in-domain (ID) method, it directly utilizes target domain demonstrations (in training-free settings) or is trained on the target domain task (in trainable settings). In contrast, the out-of-domain (OOD) method can only learn from demonstrations or training data in the source domain, and have no prior knowledge of the target domain. In this case, the model must leverage the knowledge learned from the source domain task to solve the unseen target domain task. The results show that our method consistently outperforms the baselines across various scenarios in both in-domain and out-of-domain settings, demonstrating strong task generalizability.
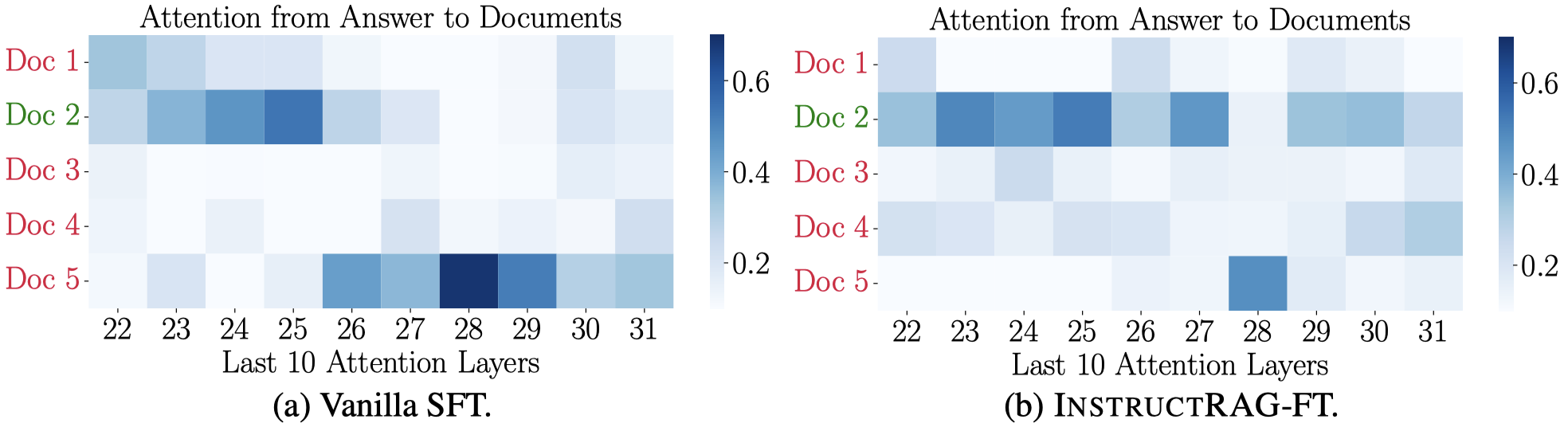
Visualization of model attention from answer to retrieved documents on a real sample from the benchmarks, where Doc 2 is the only relevant document that contains the correct answer.
This study shows that InstructRAG can effectively identify relevant information from noisy input and leverage its own knowledge to correctly answer questions when required. The red texts denote irrelevant or inaccurate model generations, while the green texts denote contents relevant to the question.

@article{wei2024instructrag,
author = {Wei, Zhepei and Chen, Wei-Lin and Meng, Yu},
title = {{InstructRAG}: Instructing Retrieval-Augmented Generation via Self-Synthesized Rationales},
year = {2024},
journal = {arXiv preprint arXiv:2406.13629},
url = {https://arxiv.org/abs/2406.13629}
}